Ryan Scott Brown
I build cloud-based systems for startups and enterprises. My background in operations gives me a unique focus on writing observable, reliable software and automating maintenance work.
I love learning and teaching about Amazon Web Services, automation tools such as Ansible, and the serverless ecosystem. I most often write code in Python, TypeScript, and Rust.
B.S. Applied Networking and Systems Administration, minor in Software Engineering from Rochester Institute of Technology.
LLM Etiquette at Work
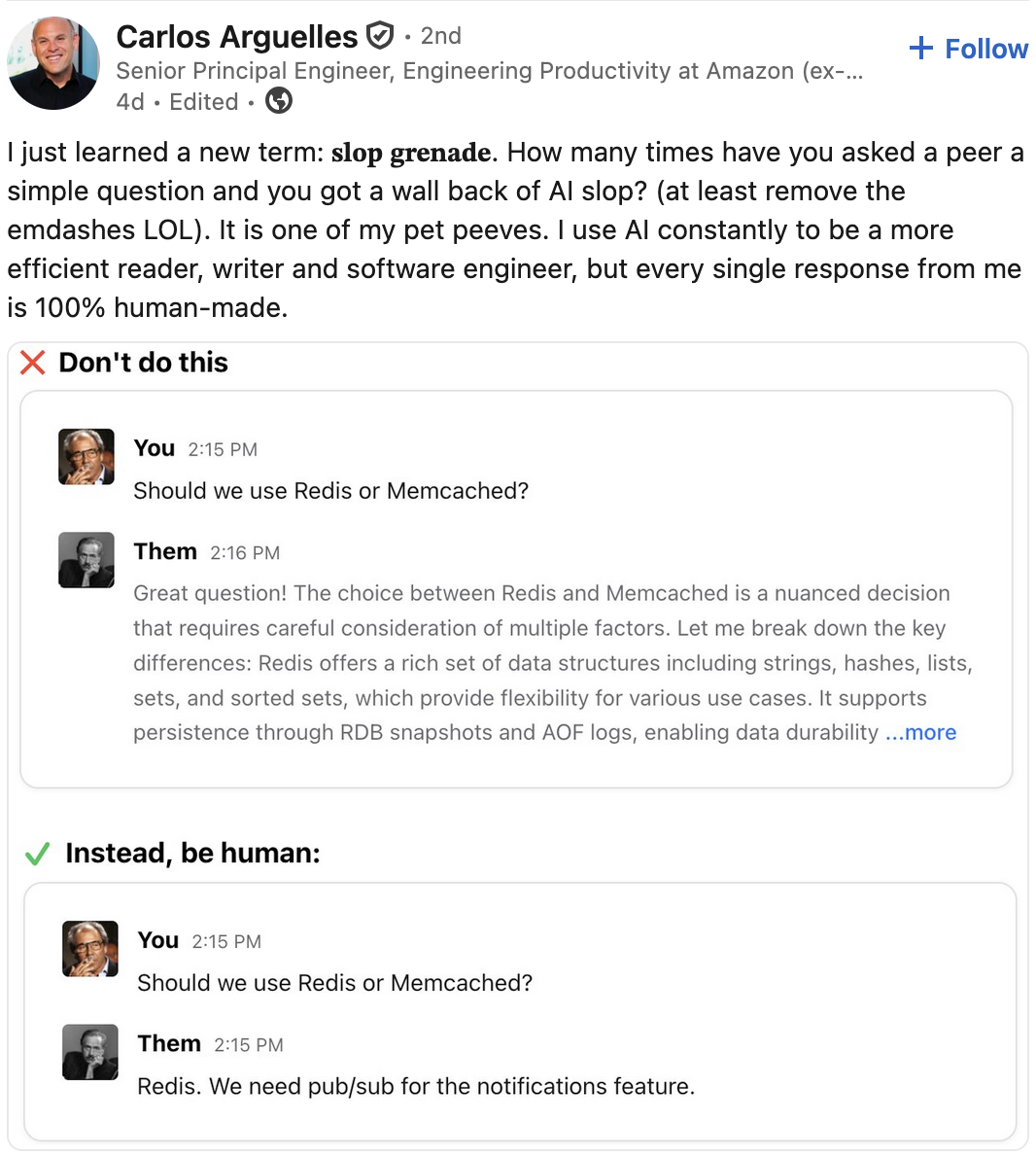
This post about the “slop grenade” got me thinking. New technology requires new social norms to go along with it.
LLMs have context distilled from the world but no sense of what’s relevant here beyond context you give them.
That nine word reply is enough of a recommendation with local context behind it. The plausible-sounding essay is a slop grenade lobbed onto my desk for me to defuse. Why does it feel so bad, and what norms we need so it stops?
LLMs are Lossy
When you ask an LLM to expound on something, you are not adding information. You are running a lossy codec that dilutes your intent.
Your actual intent lives in your head and you “prompt engineer” it (this used to be called writing). In the engineered prompt P you’re terse and lean on workplace context that you and I share, but the model does not. The model produces output O = f(P). The model never sees your intent. It only ever sees P. So the information flows in one direction:
intent -> P -> O
The data processing inequality and intuition about entropy tells us the truth about that chain:
I(O ; intent) <= I(P ; intent)
The information in the expanded artifact cannot exceed what was already in your prompt. Processing a signal can only pass through or destroy information about the source. The model can take your 12-word prompt and explode it into 600 words, but those extra 588 words carry none of your intent. They’re content that tends to follow questions/prompts like yours. Plausible detail, but not your detail. It has deep fried your JPEG of intent.

This is what generation loss causes at work. I have to decode the LLM essay back down to your intent, but I can’t be sure I recovered the right bits.
At best the LLM generates a longer, noisier encoding of the same intent your prompt held. It will hold less if you didn’t read it closely enough to catch where the model guessed wrong. The prompt was the high-signal (perhaps less polished) version. You threw it away and something lossy but polished.
None of this is an argument against LLMs, which I use constantly. When the generated artifact is the deliverable I will need to see it. The code and the prompt that made it are both important, and the prompt/plan can’t be deployed to production. This pathology is narrower and specific: it’s substituting slop for intent or judgment.
When I asked what you think I wanted your judgement. We both have the same access to LLMs but only you can access the inside of your head.
Code review is where missing intent stings
Slop grenades are being lobbed all over (email, Slack, pull requests) but design docs and code reviews are where it does the most damage. Reviews of docs and PR’s are fundamentally an exercise in matching intent to action.
A diff is a precise artifact. The diff tells me, exactly, what changed. Only tiny, clear diffs say anything about what you were trying to do or what you considered and rejected. To review your code correctly I have to reconstruct your intent from the diff, and the diff is one of the worst encodings of intent. It’s the O at the far end of the lossy chain.
This is why, when the code was written by an agent, the PR description matters more than ever. The old deal:
- You wrote the code, it takes a long time to write correct code
- I’ll read it carefully, because we both need to understand what was going into production But increasingly you aren’t writing it: you wrote a plan, steered an agent, and accepted an output. In some ways it’s cheaper to write “correct” code that works. However, does it do what you intended and is it what’s needed?
I can’t recover that from the diff. The intent rides with the change all the way to production. Your prompt, your plan, your reasoning is a first-class part of the PR. Tell me what you set out to do (or show me the ticket). Tell me which lines you’re a bit nervous about. That’s the high-signal channel that is completely empty while the diff is 15 KSLOC.
The new norms
None of this requires new tooling. It requires a few changes from all of us.
I asked you, not the model. When someone asks for your read, give your read. Not sure? Say I’m not sure, here’s my hunch. An LLM can’t say my system design made you nervous. Only you can. The moment you put your name on LLM output, every word is yours. GPT may have written it, but as far as I’m concerned, you did.
Skip the slop, just show me the prompt. If your contribution to a thread is something you typed into a model and pasted back out, your prompt was the information. Send me that. As George Kettleborough put it, you can’t create information from thin air and I have a login too. Prompt engineering is mostly good writing.
Ship the why with the what. When the artifact is the deliverable, attach the intent. Two lines of “here’s my goal and here’s the part I’m unsure about” retains the signal the LLM diluted and saves me from reverse-engineering it.
Don’t send me a low-information word problem. Update the nohello principle for the LLM era. “Hello” with no question wastes a round trip; a slop grenade with obscure intent is a zip-bomb for my mind and takes much more time than you put in to send it.
Follow the Golden Rule
Write to others like you would want to be written to. Underneath all of it is an asymmetry of effort, which is why it feels so bad to get slop-slapped.
Generating a wall of text now costs almost nothing. Reading it, deciding which parts are real, and recovering the intent costs the attention of all the readers. The slop grenade is a transfer of work from the sender to the receiver, dressed up as polish.
Why would I bother to read something you didn’t bother to write (or even read!)?
That’s etiquette. Spend the effort to review and send the high-signal version. Spare everyone downstream the work of decoding slop. The terse, human, intent-carrying answer isn’t lazy. It’s considerate, we’re all people here.